Jobs
For everything that has to run in the background (asynchronous): jobs, tasks, long-running operations, bulk processing, cleanups, notifications, etc.
A design goal is to keep the developer focussed on the application and in the mindset of the domain. Explicitly freeing you from related tasks like serialising the job payload or instrumenting it, so that the application is understandable, extensible, and maintainable.
Jobs run on top of PostgreSQL and use transactional enqueuing.
As jobs are enqueued in the same transaction as
other database operations, this prevents common issues with
background tasks in distributed systems and is an easy architecture and
simple to understand and debug.
Workers uses transaction-level locks and db operations performed in the worker
will commit or rollback with job's transaction.
Key Characteristics
Transactional queue
Simple development and exactly once guarantee (no need for distributed transactions or 2X protocols).
Different Queues
Arrower provides a default queue out of the box, but you can create as many queues as you need.
Each queue has it's own set of workers and are independent of each other.
Automatic retries on job or worker failure
Failing jobs are automatically retried with a growing backoff.
Different priorities per queue
Prioritise your jobs, so important jobs are processed first.
A time based and a priority based strategy is available.
Scheduling of jobs
Run a job at a specific time in the future.
History and insight into the Queues
With the admin UI you inspect and manage all your queues, jobs, and the history,
this gives you visibility into what is going on at all times.
Automatic instrumentation
Metrics and traces are provided automatically and can be inspected in Grafana.
The use of PostgreSQL as a backend has implications on what is possible with this setup in terms of scale but is totally fine for small to medium-sized apps.
Queue Interface
type Queue interface {
Enqueue(ctx context.Context, job Job, jobOptions ...JobOption) error
Schedule(spec string, job Job) error
RegisterJobFunc(func (ctx context.Context, job Job) error) error
Shutdown(ctx context.Context) error
}
type Enqueuer interface {
Enqueue(ctx context.Context, job Job, jobOptions ...JobOption) error
}
type Scheduler interface {
Schedule(spec string, job Job) error
}
Use the more specific interfaces Enqueuer and Scheduler as dependencies,
if you want to limit the use cases ability to manage the queue, e.g. shutdown.
Enqueue Jobs
var jq jobs.Enqueuer
// enqueue a single job
_ = jq.Enqueue(ctx, myJob{Payload: 1})
// enqueue multiple jobs as a batch operation
_ = jq.Enqueue(ctx, []myJob{{Payload: 1}, {Payload: 2}})
// enqueue multiple jobs of different kinds
_ = jq.Enqueue(ctx, []any{myJob{Payload: 1}, otherJob{}})
- If the
ctxcontains a transaction, it is used to persist the job to the database. Keeping your job consistent with your application data.
Run Job in the Future
_ = jq.Enqueue(ctx, myJob{}, jobs.WithRunAt(time.Now().Add(10*time.Minute)))
Prioritising Jobs
// a lower number means a higher priority
_ = jq.Enqueue(ctx, myJob{}, jobs.WithPriority(-1))
Repeating Tasks
Repeating tasks build on jobs. They are scheduled, and you are responsible to make sure there are enough workers to execute them on time. Consider if any peak numbers of jobs are scheduled and if it is critical that they are handled immediately if you want to avoid delayed execution.
_ = jq.Schedule("0 4 * * *", myJob{})
// with optional parameters, the cron job can be more flexible
_ = jq.Schedule("0 4 * * *", myJob{Payload: "custom-param-for-worker"})
Use the crontab format as follows:
Schedule schedules a Job repeatingly. Spec is the crontab format with some additional nonstandard definitions.
┌───────────── minute (0 - 59)
│ ┌───────────── hour (0 - 23)
│ │ ┌───────────── day of the month (1 - 31)
│ │ │ ┌───────────── month (1 - 12)
│ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
│ │ │ │ │ 7 is also Sunday on some systems)
│ │ │ │ │
│ │ │ │ │
* * * * *
`@yearly` (or `@annually`) => `0 0 1 1 *`
`@monthly` => `0 0 1 * *`
`@weekly` => `0 0 * * 0`
`@daily` (or `@midnight`) => `0 0 * * *`
`@hourly` => `0 * * * *`
`@every [interval]` where interval is the duration string that can be parsed by time.ParseDuration.
An easy way to create a cron schedule is: crontab.guru.
Process Jobs
Each job is processed asynchronously in its own worker go routine.
To be able to process jobs it is important to register a JobFunc on the appropriate queue.
The function has to have the signature of func(ctx context.Context, job YourJobType) error
var jq jobs.Queue
_ = jq.RegisterJobFunc(func(ctx context.Context, job myJob) error {
// process your job here...
return nil
})
- Returning an error will reschedule the job with an exponential backoff
- A call to
RegisterJobFuncdoes start the worker pool after a certain time.
If the worker poll got started already, subsequent calls toRegisterJobFuncwill shut it down and restart it automatically blocking your call for that time.
Accessing the Transaction of the Job
To keep your application consistent perform all db changes on the same transaction as the job.
- If the job returns without an error the transaction is committed
- If the job returns an error the transaction is rolled back and the job retried with an increasing backoff.
var jq jobs.Queue
_ = jq.RegisterJobFunc(func(ctx context.Context, job myJob) error {
tx, txOk := ctx.Value(postgres.CtxTX).(pgx.Tx)
// change db state here...
return someErr // rolls back all db changes
})
Different Queues
Arrower supports multiple job queues, but each queue has to be instantiated. If no explicit queue name is set, the default queue is used.
jq, err := jobs.NewPostgresJobs(alog.NewNoopLogger(), noop.NewMeterProvider(), noop.NewTracerProvider(), pgHandler.PGx,
jobs.WithQueue("queueName"), // set the name of the queue you want to run
)
Each queue can be configured with these optional options.
| Option | Default | Behaviour |
|---|---|---|
WithQueue | <empty> | Set the name of the queue |
WithPollInterval | 5 seconds | Set the interval to query the database for new jobs. |
WithPoolSize | 10 | Set the amount of workers |
WithPoolName | a random name | Set the a name for this worker pool instance |
WithWorkerPollStrategy | PriorityPollStrategy | Set the poll strategy |
The queue is instrumented to give you observability out of the box. You'll have logs, metrics, and traces available for you.
Testing
Job handlers are functions: test them as you would any other function.
What is remaining is to ensure the right Jobs get enqueued on the emitting site.
For this an in memory implementation of the jobs.Queue interface is available, you can use in tests. It comes
with some additional methods, to make testing easier:
- Custom assertions for the job queue
jq := jobs.NewTestingJobs()
jassert := jq.Assert(t)
// asserts the queue is empty
jassert.Empty()
_ = jq.Enqueue(ctx, myJob{})
// asserts the queue is not empty
jassert.NotEmpty()
// asserts the queue has exactly one Job of type `myJob`
jassert.Queued(myJob{}, 1)
// asserts the queue has 1 Job enqueued
jassert.QueuedTotal(1)
- Custom test helpers beyond the
jobs.Queueinterface
jq := jobs.NewTestingJobs()
// get a Job without processing it, to assert Job details.
job := queue.GetFirstOf(myJob{}).(myJob)
assert.Equal(t, "myName", job.Name)
// resets the queue to be empty
jq.Reset()
UI & Observability
See Observability for more details
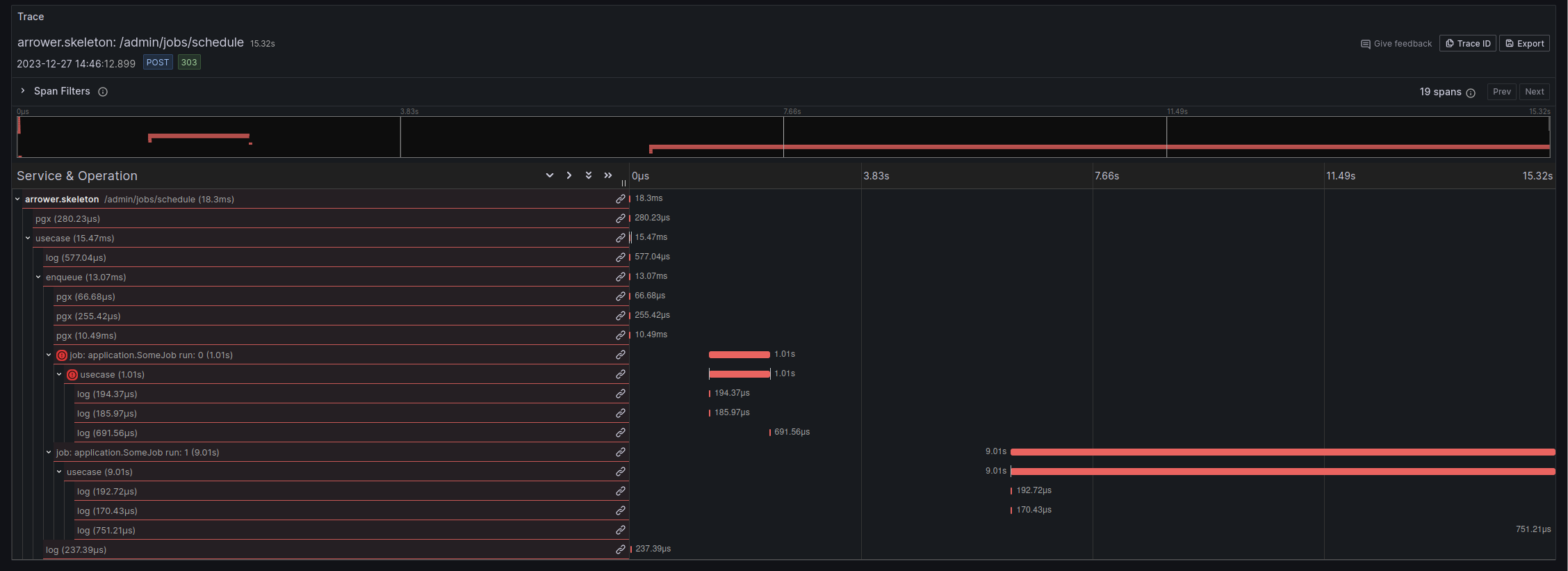
- Jobs integrate with the observability setup of Arrower
- The originating span is persisted and referenced in each Job run
- Failing Job runs are marked and retried automatically